LLM Wiki for Software Teams: Two Problems AI Agents Can't Fix Themselves
Series
Agentic Engineering
2 of 3 in the series
A series on building AI-assisted delivery systems that stay coherent: governed agents, shared product memory, and delivery workflows that reduce drift across teams and platforms.
Most multi-platform teams use AI agents as isolated workers with no shared memory. This creates two distinct failure modes: inconsistent implementations and domain blindness. They need two different fixes.
The default pattern for most teams using AI agents looks like this: upload files, ask a question, get an answer, repeat. Nothing accumulates. The next session starts from zero. This scales poorly and breaks down badly on multi-platform product teams.
In AI Agents Need Architectural Boundaries, Not Just Prompts, I argued that agentic systems need clear boundaries before teams scale capability. This article picks up the next coordination problem: even well-bounded agents drift when each platform works from isolated context.
There are two distinct problems in that space. Most teams are solving one and ignoring the other.
The LLM Wiki Pattern
Most AI-file integrations work like a library with no catalogue: the AI searches raw documents at query time, answers, and remembers nothing. Ask the same complex question tomorrow and it starts over.
The LLM Wiki pattern changes one thing: the AI does not retrieve from raw documents at query time. It builds and maintains a compiled knowledge layer that sits between you and the raw sources.
Think of the difference as two libraries. The first has no catalogue. Every query requires a full-building search that misses connections across sources. The second has a librarian who has already read everything: written summaries, drawn cross-references, noted contradictions, built an index. When you ask a question, most of the answer is already there. Every new book gets read and integrated into the whole system.
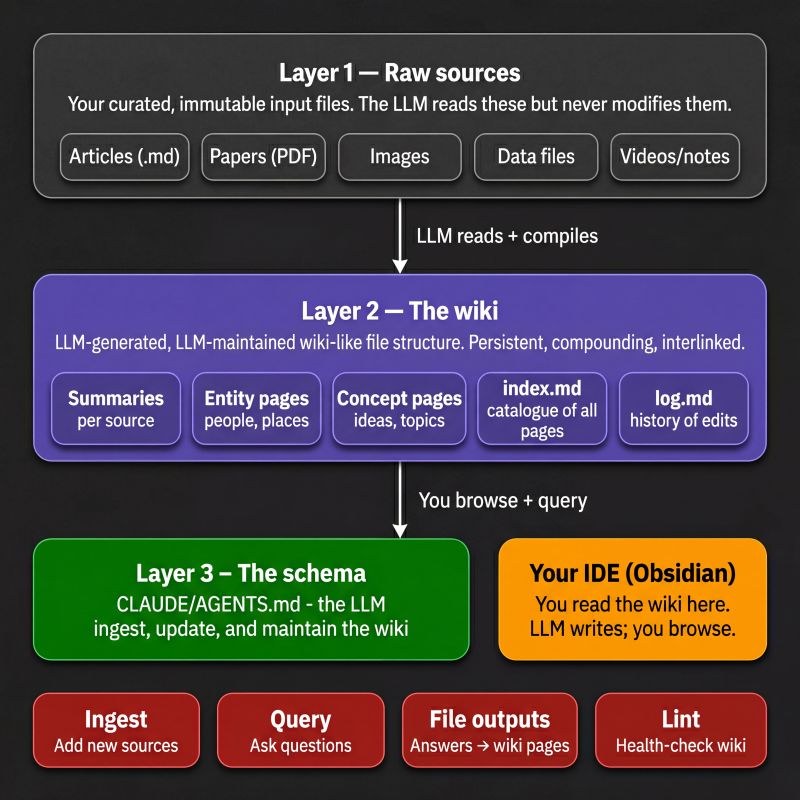
The architecture has three layers: raw sources, which the AI reads but never modifies; the wiki itself, which is LLM-authored and LLM-maintained; and the schema, the project instructions file that tells the AI how to structure and maintain the wiki. The operations are ingest, query, file outputs, and lint. Those commands keep the system running.
The human's job is to source material and ask good questions. The AI handles the summarising, cross-referencing, filing, and bookkeeping that makes a knowledge base useful over time. Humans abandon wikis because maintenance burden grows faster than value. The AI does not get bored, does not forget to update a cross-reference, and can touch fifteen files in a single pass.
This shifts the AI's role from search engine over your files to author and keeper of your knowledge.
Applying This to a Multi-Platform Product Team
When you are building a product across multiple platforms, backend, web app, admin portal, Android, and iOS, you encounter a coordination problem that almost nobody names precisely. It is actually two problems. Most teams are solving only one.
Problem One: Context Broadcasting
You have a new feature. You have a spec. You have design files. You have advisory notes. Now you need to implement it across five separate codebases, each with its own AI agent.
So you copy and paste context into each agent manually. You repeat yourself. You hope you said the same thing consistently. Then the feature evolves and you do it again.
There is no shared memory. No compounding. Every session starts from zero. Each agent has only heard what you told it in that session.
Two days later, each platform has implemented a slightly different version of the same thing. Not broken exactly, just inconsistent in the ways that are hard to catch until they matter. The Android app makes an API assumption the backend never agreed to. The iOS flow handles an edge case differently from the web app. These are not bugs in the traditional sense. They are the natural result of isolated agents working from isolated context.
This is the context broadcasting problem. It has three compounding dimensions.
Inconsistency. There is no single source of truth for what the feature actually is. Each agent's understanding may subtly differ from every other agent's.
No memory. Every session is stateless. The iOS agent that helped you build the authentication flow last month knows nothing about it today. You will repeat yourself indefinitely.
No compounding. The AI's understanding of your product never grows. Feature twenty is implemented with the same context poverty as feature one. None of the hard-won decisions, architectural trade-offs, or "we tried this and it didn't work" moments accumulate anywhere the AI can access.
The Fix for Problem One: The Product Wiki
Apply the LLM Wiki pattern to the product itself. The wiki becomes the shared brain of your entire development system: a layer that lives in the root of your monorepo, maintained by the AI, and read by every platform agent.
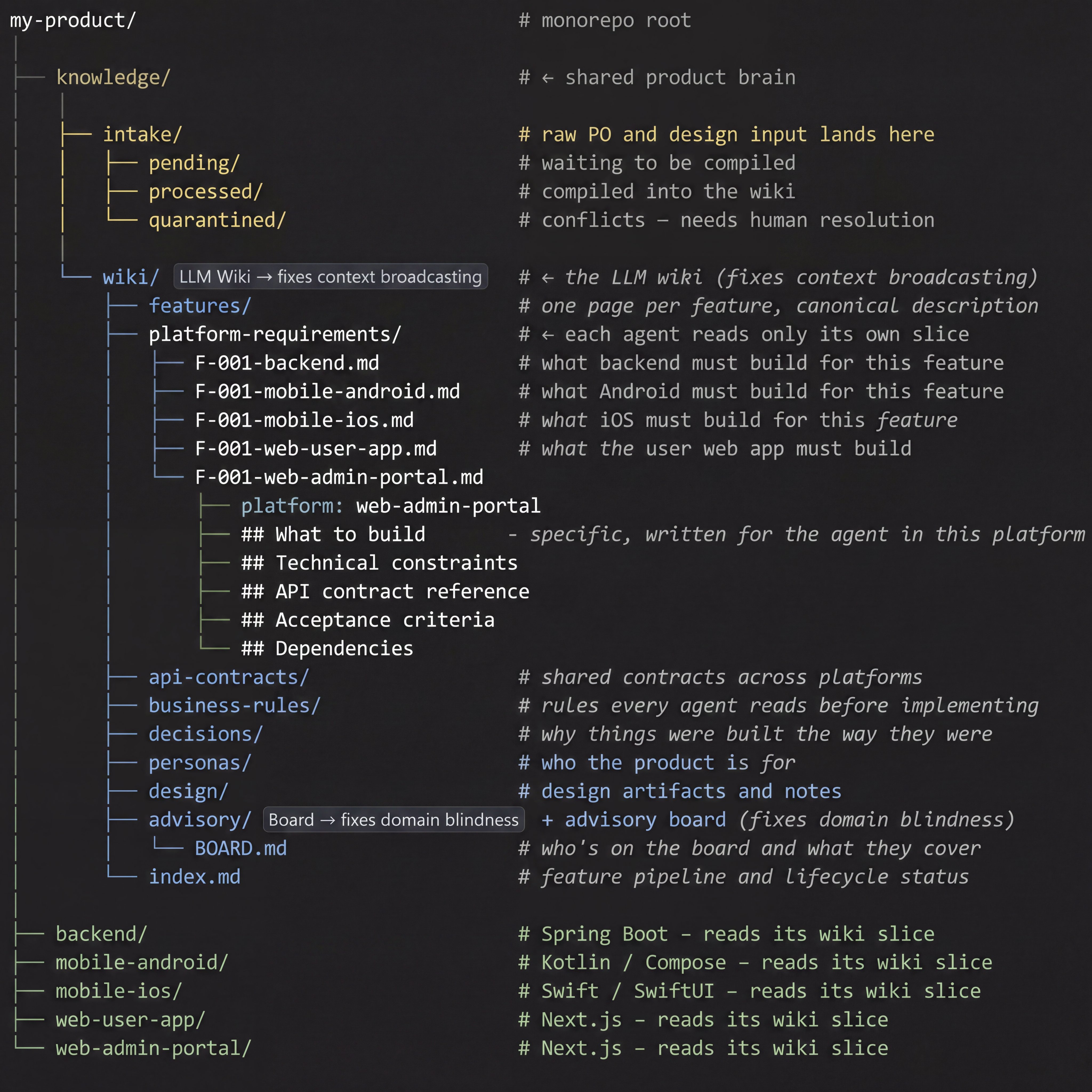
At the monorepo root sits a knowledge/ directory. It has two major sections.
The Intake Layer
The intake layer is where raw material enters the system. Product owners, designers, and project leads drop specs, design files, meeting notes, and feature requests into intake/pending/. The AI's job is to compile them into the wiki.
The quarantined/ directory is important and often overlooked. When the AI detects that new input conflicts with something already established in the wiki, such as a contradictory API assumption or a feature that undermines a previous architectural decision, it does not silently overwrite existing knowledge. It moves the conflicting input to quarantine and flags it for human resolution. Conflicts need a human decision, not an AI overwrite.
The Wiki Layer
A few directories are worth expanding on.
business-rules/ contains rules that every agent reads before implementing anything, not feature-specific logic, but product-wide constraints. Things like "all user-facing operations must be reversible," "data returned from the API must never include raw database IDs," or "all monetary values are stored and transmitted in minor currency units." These are the rules that get violated when an agent is given only a feature spec and no broader product context.
personas/ defines who the product is for. Not demographics, but actual behavioural patterns, goals, and constraints of the people using each part of the product. An agent implementing a feature for the admin portal should know that the admin persona is a non-technical operations user, not a developer. That context changes implementation decisions significantly.
decisions/ records why things were built the way they were: Architectural Decision Records filed as the product evolves, visible to every agent and every advisory review that comes after.
Each platform-requirement file has a consistent internal structure: what to build, specific to this platform and its architecture; technical constraints; API contract reference; acceptance criteria; and dependencies. The Android agent opens F-001-mobile-android.md and finds a spec already written in the context of Kotlin and Jetpack Compose. It does not have to infer from a generic product description what the feature means for its platform. That translation was done once, when the feature was introduced.
The Platform Agents
Each platform's AI context file, the project instructions file each agent reads on startup, contains a simple protocol: before implementing any feature, read knowledge/wiki/index.md, find the relevant feature page and your platform-requirements page, and treat those as the source of truth for what to build.
This is the entire coordination mechanism. No manual relay of context between sessions. No inconsistent paraphrasing of the same spec into five different chat windows. The wiki is the shared memory. The agents read from it.
Context is broadcast once. It accumulates. It compounds.
Problem Two: Domain Blindness
Here is the problem that better agent alignment will not fix.
Your agents can be perfectly in sync with each other and still ship the wrong thing. Not wrong technically, but wrong in ways that nobody on the team thought to question. The logic made sense to everyone in the room. The code is clean. The feature ships. And then something fails that no amount of code review would have caught.
A feature that affects how people make decisions, designed without anyone who understands behavioural psychology in the loop. An assumption about users that does not hold in certain cultures, because everyone in the room came from the same background. A compliance assumption that turns out to be incorrect, because nobody with that domain expertise reviewed it before implementation started.
These things do not show up in code review. They show up after launch.
This is the domain blindness problem. It does not care how good your prompts are or how well-aligned your agents are. It is a structural gap in who reviews a feature before work begins.
The AI agent is not the right tool to fix this. An AI that reads your product wiki can catch technical inconsistencies and architectural drift. It cannot tell you that the habit-formation model underlying your notification feature ignores what behavioural science says about user autonomy. That requires a human with the right background, and the right question asked at the right time.
The Fix for Problem Two: The Advisory Board
The advisory board is the domain expertise layer: the group of people, internal or external, who review features for the things the core team is not equipped to catch.
This is not a code review or an architecture review. It is domain expertise, specific to what this product could get wrong. The composition depends entirely on the product:
- A behavioural psychologist if your product touches habit, motivation, or decision-making
- A compliance or legal perspective if it handles regulated data or operates in a regulated industry
- A cultural or accessibility specialist if your user base spans backgrounds the team does not represent
- A security researcher if features touch authentication, data sharing, or privacy boundaries
The critical detail is timing. Advisory review happens before a line of code is written. It does not happen in parallel with implementation or in a post-launch retrospective. The review feeds back into the wiki under knowledge/wiki/advisory/ and becomes part of the compiled context that platform agents read before they implement.
BOARD.md defines who is on the board and what domain each member covers. When the AI generates a review-feature output, it reads the board composition and frames questions and risks in terms of each member's domain. The output is targeted. "This feature has a habit-formation dimension that the behavioural perspective should evaluate" is more useful than "consider user experience."
By the time you are working on feature fifteen, the advisory review of feature sixteen is informed by fifteen previous reviews. Patterns of risk become visible. The same assumption appearing across multiple features gets flagged. The board effectively accumulates memory, the same way the rest of the wiki does.
Two Problems, Two Different Fixes
The distinction is worth being precise about, because confusing them leads to applying the wrong solution.
Context broadcasting is what happens when agents implement inconsistent versions of the same feature. The platform agents miss it, each working from isolated context. It surfaces during implementation and integration. The fix is the product wiki, which compounds product knowledge, architectural decisions, and API contracts.
Domain blindness is what happens when the entire core team builds the wrong thing correctly. The right expertise was never in the room. It surfaces after launch. The fix is the advisory board, which compounds domain expertise, risk patterns, and questions the team did not know to ask.
The wiki keeps your agents consistent with each other. The advisory board keeps your team from building the wrong thing consistently. Most teams today are solving the first problem and hoping the second one never happens.
The question worth asking is not "are our agents aligned?" It is: did the right people ask the right questions before we started?
The Four Operations That Keep the System Alive
The wiki is not static documentation. It is a living system maintained through four defined operations, each triggered as a command to the AI agent.
Introduce feature. Drop a spec and supporting materials into intake/pending/feature-XXX/. The AI reads everything, compiles it into the wiki: canonical feature page, platform requirement pages, API contract, and updated index. It then moves the raw material to intake/processed/. If anything conflicts with existing wiki knowledge, it goes to intake/quarantined/ instead, with a note on what needs human resolution before the feature can proceed.
Review feature. The AI reads the new feature page alongside the entire history: all previous features, all past API contracts, all previous advisory reviews, and all architectural decisions. It produces an advisory review page informed by everything that came before. It reads BOARD.md and frames domain-specific questions for the relevant board members. This page becomes part of the wiki before implementation starts.
File decision. When a significant architectural or product decision is made, whether in a meeting, a code review, or an advisory session, it gets filed as an Architectural Decision Record in wiki/decisions/. The AI formats it consistently and updates the index. Future agents and future advisory reviews read the decision log and are constrained by it.
Lint wiki. Periodically, the AI health-checks the entire wiki. It looks for features that exist in wiki/features/ but are missing one or more platform-requirement pages. It finds API contracts that contradict platform requirements. It identifies concepts referenced frequently across pages that have no dedicated page. It flags entries in intake/quarantined/ that have been waiting for human resolution. The output is a health report and a prioritised list of gaps to address.
What This Looks Like in Practice
A product manager wants to introduce a user profile editing feature to a product with a Spring Boot backend, Next.js web and admin apps, Jetpack Compose Android, and SwiftUI iOS.
- They drop a spec and a design export into
intake/pending/feature-012/ - The AI runs introduce-feature, producing seven wiki pages: the canonical feature page, five platform-requirement pages, and an API contract. It also flags in the index that this feature touches the authentication data model addressed in feature-003
- The AI runs review-feature. The output notes that the profile editing flow involves user consent for data changes, a domain the behavioural perspective on the board should evaluate, and that the proposed data model has a compliance implication the legal perspective should clear before implementation starts
- The board reviews. A decision is filed in
wiki/decisions/. The feature page is updated with the outcome - The backend agent reads
platform-requirements/F-012-backend.mdand implements exactly what it says, constrained by the API contract and thebusiness-rules/context it reads before starting any feature - The Android agent reads
platform-requirements/F-012-mobile-android.mdand implements the UI, knowing precisely what the API will return and what the acceptance criteria are
At no point did a human manually copy context from one agent session to another. At no point did two platform agents interpret the same spec independently and drift. At no point did the feature reach implementation without the right domain expertise having reviewed it.
The Honest Challenges
This system is not free. There are real friction points worth being clear about.
Workflow discipline at intake is the hardest part. The system only works if features enter through the wiki before anyone starts implementing. If developers write code first and file the spec retroactively, the wiki lags reality and loses trust. This is a culture problem more than a technical one, and it is the hardest one to solve.
Advisory timing requires real commitment. The advisory board review is only useful if it happens before implementation begins. A review that happens in parallel with coding, or after a PR is already open, is too late to change the fundamental assumptions of the feature. Teams that adopt the board but skip the timing discipline get the overhead without the benefit.
Context window scoping at scale. At an early-stage product, every agent can read the full wiki index easily. At a mature product with a hundred features, naive reading of everything becomes slow. The platform-requirement structure is designed to help because each agent reads only its own slice. But index.md and SCHEMA.md need to be written carefully to enable efficient navigation as the wiki grows.
Command quality determines output quality. The lint-wiki and review-feature operations are only as good as the prompts that drive them. A generic prompt produces generic output. These commands need to explicitly instruct the AI to check against named features, reference the decision log, and flag specific conflicts. This prompt engineering work is worth investing in early because it is what separates a genuinely useful advisory review from boilerplate.
How to Start
The starting point is deliberately minimal:
- Create a
knowledge/directory in your monorepo root with theintake/andwiki/subdirectory structure described above - Write a
SCHEMA.mdinsidewiki/that defines what pages exist, what they contain, and how they should be named. This is the document that tells the AI how to maintain the wiki - Write an
index.mdthat the AI maintains as a catalogue of all pages and the status of the feature pipeline - Write
wiki/advisory/BOARD.mdthat names who is on the advisory board and what domain each person covers, even if the board starts with two people - Add a section to each platform's AI context file instructing the agent to read
knowledge/wiki/index.md, the relevant platform-requirements pages, andbusiness-rules/before implementing any feature - Introduce your next feature by dropping a spec into
intake/pending/and asking your AI agent to compile it into wiki pages following the schema
That is the entire setup. The compounding starts immediately. By the time you have introduced three or four features this way, the difference from your current workflow will be noticeable, not because the individual agents are smarter, but because they are working from a shared context that keeps getting richer.
The Bigger Picture
What is described here is a shift in how AI agents participate in product development.
Today, most teams use AI agents as fast typists. They generate code well. They maintain coherent product understanding poorly. And they have no mechanism at all for catching what a domain expert would catch. Teams compensate by doing the context management work themselves, which is slow, error-prone, and does not scale.
The product wiki solves the first gap. The advisory board solves the second. Neither is a product. Neither requires new tooling. Both are patterns that can be instantiated in any monorepo today, with any AI agent that can read files and follow instructions.
The teams that figure out both patterns now will have a structural advantage: their agents work from accumulated product intelligence, and their features are reviewed by the right people before implementation starts. That advantage compounds with every feature shipped.